0. 트라이(Trie)
트라이(Trie)는 문자열을 저장하고 호율적으로 탐색하기 위한 트리 형태의 자료구조이다.
트라이는 Retrieval Tree에서 나온 단어로 검색할 때 사용되는 자동완성 기능, 사전 검색 등 문자열 탐색에 특화되어 있다.
단, 각 노드에서 자식들에 대한 배열을 모두 저장하고 있다는 점에서 저장 공간의 크기가 크다.(메모리 복잡도에서 비효율적임)
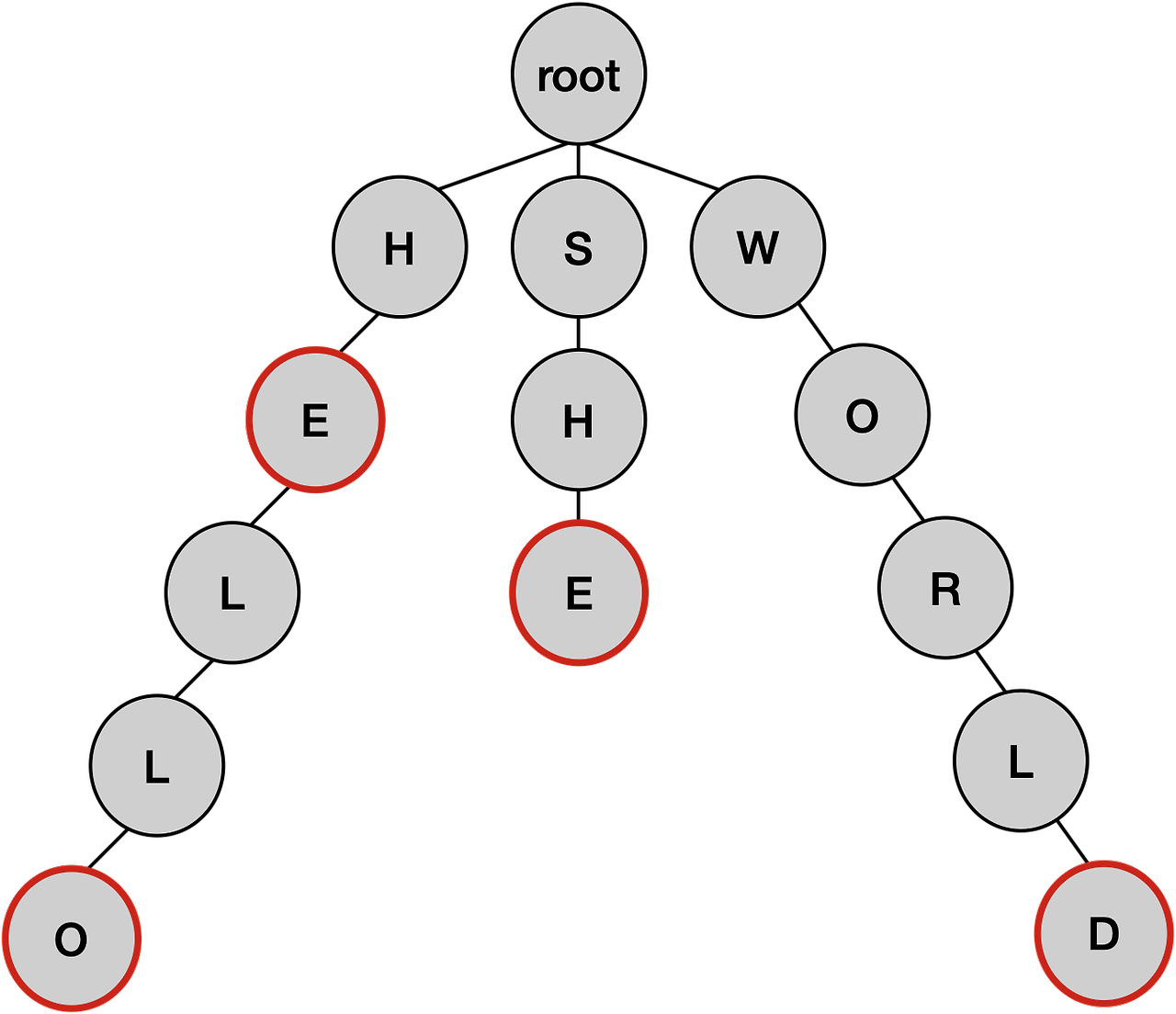
0-1. 트라이 자료구조의 노드 구조
트라이의 노드는 4개의 정보를 담고 있다.
- key: 현재 노드의 알파벳
- data: 현재 노드까지의 결과 -> 완성된 문자열
- endOfWord: 현재 노드로 이루어진 단어가 있는지 판단하는 변수
- children: 자식 알파벳 노드들
1. 트라이(Trie) 연산
1-1. 삽입
- 첫번째 문자가 trie head의 자식 노드에 있는지 확인
- 있다면 해당 노드로 이동
- 없다면 해당 노드 생성 후 이동
- 그 다음 문자가 현재 노드의 자식 노드에 있는지 확인
- 있다면 해당 노드로 이동
- 없다면 해당 노드 생성 후 이동
- 남은 문자열만큼 2번 반복
- 마지막 노드에 끝남을 알리기 위해 endOfWord를 true로 바꾼 후, data에 문자열을 저장해준다.
1-2. 삭제
- trie head에서 첫번째 문자의 자식 노드가 있는지 확인
- 있다면 해당 노드로 이동
- 없다면 해당 문자열은 존재하지 않으므로 Error
- 현재 노드에서 그 다음 문자의 자식 노드가 있는지 확인
- 있다면 해당 노드로 이동
- 없다면 해당 문자열은 존재하지 않으므로 Error
- 남은 문자열만큼 2번 반복
- 마지막 노드에 도달했다면 endOfWord를 false로 바꾼다.
1-3. 탐색
- trie head에서 첫번째 문자의 자식 노드가 있는지 확인
- 있다면 해당 노드로 이동
- 없다면 해당 문자열은 존재하지 않으므로 Error
- 현재 노드에서 그 다음 문자의 자식 노드가 있는지 확인
- 있다면 해당 노드로 이동
- 없다면 해당 문자열은 존재하지 않으므로 Error
- 남은 문자열만큼 2번 반복
- 마지막 노드에 도달했다면 endOfWord 값 확인
- true라면 해당 노드의 data 출력
- false라면 해당 문자열은 존재하지 않으므로 Error
2. 코드
반응형